Summarizing Scientific Articles: Experiments with Relevance and Rhetorical Status

Information Retrieval and Extraction
Monsoon 2018
Richa Kushwaha (20172056)
Sudheer Achary (20161076)
Swati Tyagi (20172096)
P. Sai Vasishth (201501179)
Mentor:
Bakhtiyar Syed
What is the project ?
We want to summarize a research paper. We classify each sentence within the research paper as one of the rhetorical categories. This will help getting a summary of the paper.
Aim
- Compile a data set of research papers and annotate them.
- Extract features out of each sentence and train a classifier.
- Idea for a deep learning framework to achieve the task.
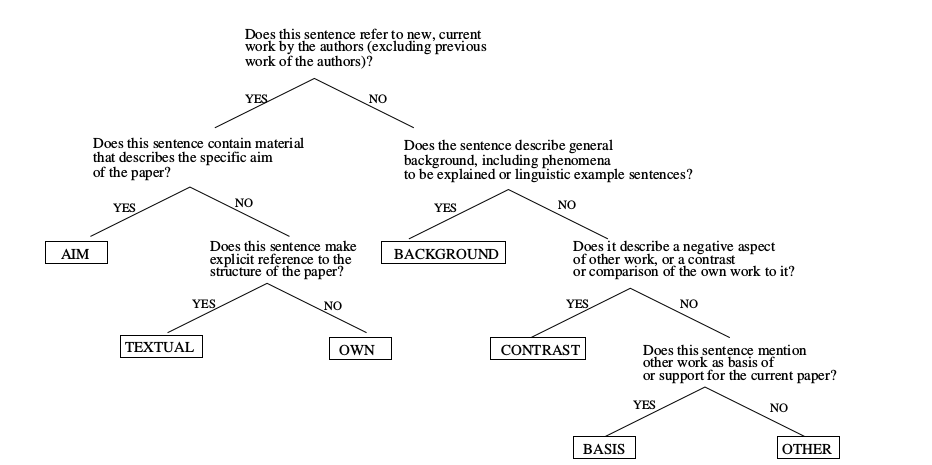
Classes: Annotations for each sentence

How to annotate ? - Decision Tree
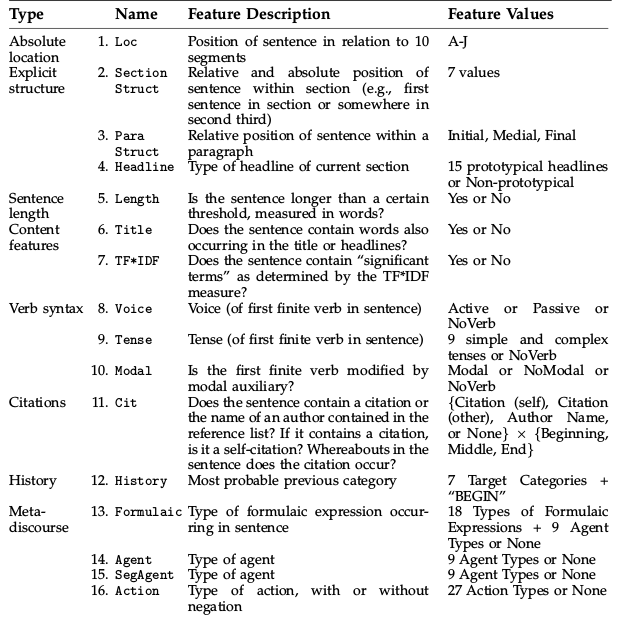
Features
Annotation and Observations
- Papers annotated were based on psychological diseases.
- A minimum knowledge about the domain related to the paper is must.
- A basic understanding of the paper (at least abstract) is must.
- Previous and Future context (of a sentence) both matter.
- Summary Papers are difficult to annotate
Implementation
- xml python package to parse through the data(in xml format) easily.
- Features described earlier were extracted and passed to a Naive Bayes model.
- Bernoulli, Multinomial, Gaussian, Compliment were the distributions assumed.
- Model was trained and tested on different sets of data, such that ratio of train test split was maintained to ~0.8.
Results
- Bernoulli distribution gave highest of 80% accuracy.
- Deep network (explained later) gave around 71% .
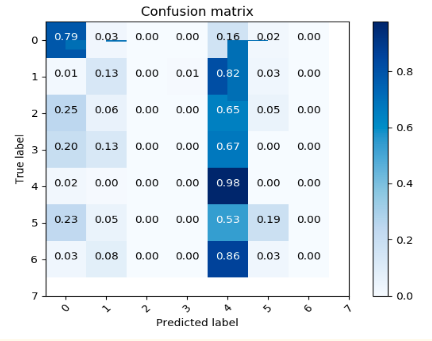
81% accuracy. Bernoulli distribution
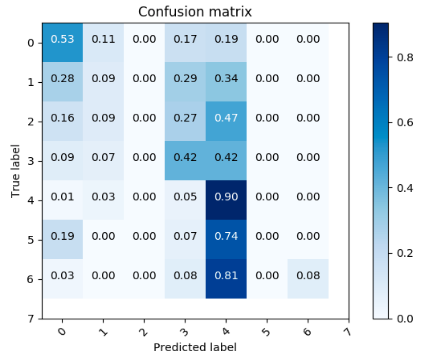
72% accuracy. Multinomial distribution
Deep Learning model
- Stanford GloVe embeddings as features for each word.
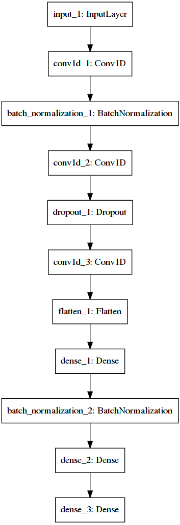
- Used Convolutional layers with different set of activations & filters, followed by Dropouts & Batch Normalization finally stacked with Dense layers for one hot categorical classification.
- Used Adamax optimizer for gradient descent, categorical cross entropy loss as it is an multiclass classification problem.
- Main problem we faced for less data which makes the model to learn the most probable class rather than classify based on sentencial features
Deep Learning Architecture
Future Work
- Improve deep learning model by increasing word vector size.
- In the deep learning model, use a bi-LSTM to maintain temporal information across sentences.
- Our model's outputs are inputs to the bi-LSTM. This can improve the classification better. Using a bi-LSTM also caters to taking future and past contexts.
- Getting more data as current data is very less to train a DL model.